シェル芸が好きな割には普段 s コマンドしか使っていないので、思いつく使い道を洗い出してみる
思いつき次第追記するかもしれない
前提として、他のPOSIXコマンドのほうが早い用法はなるべく避けたい
例:ただ単に y/source/dest/ コマンド使うだけなら tr source dest で良いよね
使用バージョンは下記
$ sed --version
sed (GNU sed) 4.8x〜y行目だけを抽出する
head | tail するよりも直感的でわかりやすい
$ seq 10 | sed --posix -n 2,5p
2
3
4
5何が起きているか
sedは何もコマンドを入れない限り入力を出力に素通りさせる
$ seq 10 | sed --posix '' # コマンドが空文字
1
2
3
4
5
6
7
8
9
10-n オプションをつけると、デフォルトで入力を出力に通さなくなる
$ seq 10 | sed --posix -n ''
# 何も出ないsedのスクリプトは[アドレス][コマンド]の組み合わせで構成される
今回は 2,5 がアドレスで p がコマンドになっていた
普段 sed 's/regex/replacement/flag' を使っているのは、アドレス省略=全行と s コマンドの組み合わせになっている
類似のコマンド
$ seq 10 | sed --posix -n '4p;6p' #4行目だけ出すコマンド、6行目だけ出すコマンド
4
6改行をまたぐ文字列の置換を行う
次行の読み込み( N コマンド)を行うことで、2行分の置換を繰り返す
下記のようなファイルがあるとする
$ cat 8width.txt # a~zを繰り返しているだけ
abcdefgh
ijklmnop
qrstuvwx
yzabcdef
ghijklmn
opqrstuv
wxyz「h(改行)ij」を置換する場合
$ cat 8width.txt | sed --posix -E '$!{N;s/h\nij/#\n##/;P;D}'
abcdefg# ←ここが変わってる
##klmnop
qrstuvwx
yzabcdef
ghijklmn
opqrstuv
wxyz「hij」という文字列があったら改行関係なく書き換えたいという場合
(ただしこれは固定長を前提にしている。 別にtr -d \\n | sed | fold -w8 でもいいのでsedで完結させることの優位性は微妙。)
$ cat 8width.txt | sed --posix -E '$!{N;s/\n//;s/hij/###/;s/^.{8}/&\n/;P;D}'
abcdefg# ←ここが変わってる
##klmnop
qrstuvwx
yzabcdef
g###klmn ←ここも変わってる
opqrstuv
wxyz何が起きているか
sedの処理系には「Patttern Space」という領域が存在する
各コマンドの処理を行う際は、pattern space内の文字列に対して実行されている
| 処理 | 入力行 | pattern space | 出力 |
|---|---|---|---|
| 行の入力 | line:before | ||
| pattern spaceに上書き | line:before | ||
s/before/after/実行 | line:after | ||
| 処理完了 | line:after | line:after |
s/before/after/ コマンドを実行するときの各領域余談だが、 -n オプションを与えたときは処理完了時の出力が省略され、明示的に p コマンドを実行したタイミングでその時点のpattern spaceが出力される
毎行入力をpattern spaceに上書きしているため、よくある「sedで行またぎの置換ができない!」という悩みが出るのも無理はない
が、 N コマンドを使用することで次の行をpattern spaceに追記することができる
問題の sed -E '$!{N;s/h\nij/#\n##/;P;D}' を実行するときは下記のようになっている
| 処理 | 入力行 | pattern space | 出力 |
|---|---|---|---|
| 行の入力(上書き省略) | abcdefgh | abcdefgh | |
N 実行(次行を追記) | ijklmnop | abcdefghijklmnop | |
s/h\nij/#\n##/実行 | | | |
P 実行(1行だけ出力) | | | |
D 実行(1行だけ削除し、先頭コマンドからやり直し) | | ||
次の N 実行(以降繰り返し) | qrstuvwx | qrstuvwx |
ちなみに、 コマンド列中の $! は「最終行( $ )以外( ! )」というアドレスを意味している
最終行も N コマンドを実行してしまおうとすると、次の行がないためその時点で終了してしまう(今回は -n オプションを使用していないため、途中で終了すると最終行を出力する機会がなくなる)ため、最終行だけ回避している
2行以上の空白を1行に圧縮する
下記のようなファイルがあるとする
$ cat random_newline.txt
2 newlines below
3 newlines below
1 newline below
3 newlines below
endlabelを使えば重複する改行をループで取り除ける
$ sed --posix -nE ':top;$p;N;s/^$\n^$//;ttop;P;D' random_newline.txt
2 newlines below
3 newlines below
1 newline below
3 newlines below
endPOSIXのマニュアルに別解があったぜ(記事書いているときに気づいた)
https://pubs.opengroup.org/onlinepubs/9699919799/utilities/sed.htmlsed -n '
# Write non-empty lines.
/./ {
p
d
}
# Write a single empty line, then look for more empty lines.
/^$/ p
# Get next line, discard the held <newline> (empty line),
# and look for more empty lines.
:Empty
/^$/ {
N
s/.//
b Empty
}
# Write the non-empty line before going back to search
# for the first in a set of empty lines.
p
'
何が起きているか
sedにはラベルとジャンプ(いわゆるgoto)のコマンドが用意されている
| コマンド | 処理内容 |
|---|---|
: label | ラベルを設置する。特に何もしない |
b label | branchコマンド。無条件にlabelにジャンプする |
t label | testコマンド。 最後の行入力か t コマンド実行以降、s コマンドが実行していればlabelにジャンプする |
それを踏まえ、今回のコマンドは下記のように処理が進んでいる
| コマンド | 処理 |
|---|---|
: top | 「top」と言う名前のラベルを設置 |
$p | 最終行はそのまま出力する |
N | 次行をpattern spaceに読み込む 前項と同様、複数行置換を実施するための処理 |
s/^$\n^$// | 空行が2行あったら、削除する |
t top | s コマンドに成功した場合、top のラベルまでジャンプする |
P | 1行だけ出力する |
D | 先頭行を削除し、コマンド列の先頭に戻る |
:top;$p;N;s/^$\n^$//;ttop;P;D の実行処理5行おきにテーブルの見出しを再掲する
hold spaceを使うことで、テーブルの見出しを保存して定期的に出力できる
$ cat tables.txt
+----+------+
| No | Name |
+----+------+
| 1 | AAA |
| 2 | BBB |
| 3 | CCC |
| 4 | DDD |
| 5 | EEE |
| 6 | FFF |
| 7 | GGG |
| 8 | HHH |
| 9 | III |
| 10 | JJJ |
| 11 | KKK |
| 12 | LLL |
+----+------+$ cat tables.txt | sed --posix -En '1{N;N;h};p;/[05] \|/{g;p}'
+----+------+
| No | Name |
+----+------+
| 1 | AAA |
| 2 | BBB |
| 3 | CCC |
| 4 | DDD |
| 5 | EEE |
+----+------+
| No | Name |
+----+------+
| 6 | FFF |
| 7 | GGG |
| 8 | HHH |
| 9 | III |
| 10 | JJJ |
+----+------+
| No | Name |
+----+------+
| 11 | KKK |
| 12 | LLL |
+----+------+何が起きているか
sedの処理系には「Pattern Space」以外に「Hold Space」という領域が存在する
対応するコマンドを用いることで、pattern spaceとhold space間で内容のコピーや追記を行うことができる
| 処理 | 入力行 | pattern space | hold space | 出力 |
|---|---|---|---|---|
| 行の入力 | +----+------+ | | | |
| pattern spaceに上書き | +----+------+ | |||
N;N を実行 | | No | Name |+----+------+ | +----+------+| No | Name |+----+------+ | ||
h 実行pattern spaceを hold spaceにコピー | | | +----+------+| No | Name |+----+------+ | |
p 実行 | | | | |
次行入力、 p 実行 | | 1 | AAA | | | | | 1 | AAA | |
| (中略) | | |||
| No.5の行入力 p 実行 | | 5 | AAA | | | 5 | AAA | | | | 5 | AAA | |
/[05] \|/ にマッチするため g 実行hold spaceを pattern spaceにコピー | | | ||
p 実行 | | | |
1{N;N;h};p;/[05] \|/{g;p}の処理内容/[05] \|/を謎に思う人がいるかもしれないが、これもアドレス指定の方法である
数字や $ の代わりに /regex/ と書くことで、その正規表現にマッチする行に絞ってコマンドを指定できる
今回は1の位に0か5を持つ行という絞り方をした
(gnu拡張を使うと5n+3行目といった表現ができるのだが、それは別のお話)
初めてHold Spaceを見たときに使い道がわからず、調べても「全行を逆順に出力する」程度のいつ使うのかわからない使い道しか見つからなかったため要らない機能だと思っていたが、名前通り単純に「内容を保持する」ために使ってあげれば良いということに思い至った
おまけ:xxdコマンドの出力から特定バイナリ列をgrepする
あまりにも難産でコマンドが複雑になったので、見てもらったほうが早い
ランダムなバイト列から、「0xc2」が対象となる箇所をハイライト表示し、行末に「###」をつけている
$ xxd random.bin | sed --posix -En '$bl4;N;s/^([[:xdigit:]]+): (((\x00?[[:xdigit:]]\x01?){4} ){8}) (.{16})\n([[:xdigit:]]+): (([[:xdigit:] ]{4} ){8}) (.{,16})/\1:\6:#\2\7:\5\9/;:l1;s/#((\x00?[[:xdigit:]]\x01?){4}) /\1#/;tl1;:l2;s/([[:xdigit:]]+:[[:xdigit:]]+:[[:xdigit:] #:]+)(c2)([[:xdigit:] #:])/\1\x00\2\x01\3/;tl2;:l3;s/((\x00?[[:xdigit:]]\x01?){4})#/#\1 /;tl3;s/#((\x00?[[:xdigit:]]\x01?){4} ){8}/&#/;s/#(.*\x00[[:xdigit:] ]+)#/#\1\x01#/g;s/#([[:xdigit:] ]+\x01[[:xdigit:] ]+):/#\x00\1:/;s/^([[:xdigit:]]+):([[:xdigit:]]+):#([^:]*)#([^:]*):(.{16})(.{,16})$/\1: \3 \5\n\2: \4 \6/;s/^(.*\x00.*)\n/\1 ###\n/;:l4;s/^([^\n]*)\x00/\1\x1b\[31m/;s/^([^\n]*)\x01/\1\x1b\[m/;tl4;P;D'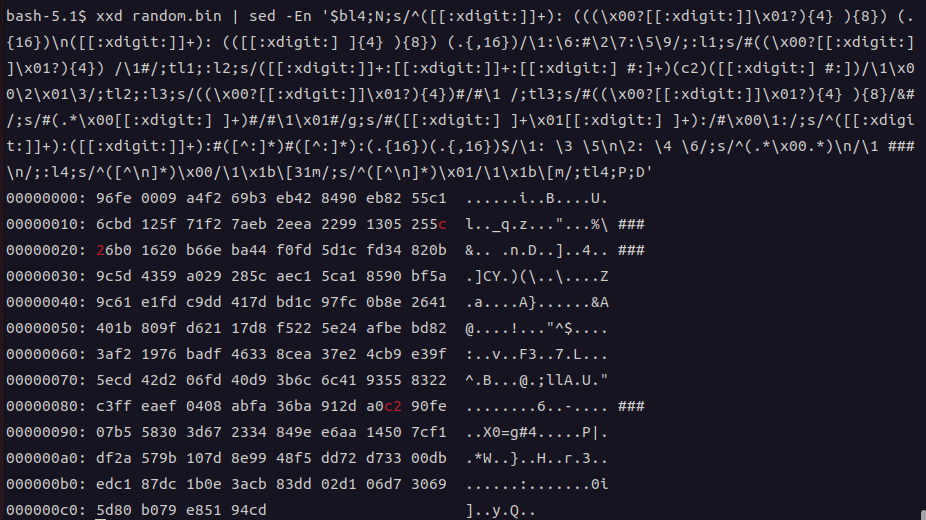
ワンライナーでやるのに限界を感じたのでせめてスクリプトにしましょうね
$ cat xxdgrep.sh
#!/bin/bash
sed -En "
\$bl4
N
s/^([[:xdigit:]]+): (((\x00?[[:xdigit:]]\x01?){4} ){8}) (.{16})\\n([[:xdigit:]]+): (([[:xdigit:] ]{4} ){8}) (.{,16})/\1:\6:#\2\7:\5\9/
:l1
s/#((\x00?[[:xdigit:]]\x01?){4}) /\1#/
tl1
:l2
s/([[:xdigit:]]+:[[:xdigit:]]+:[[:xdigit:] #:]+)($1)([[:xdigit:] #:])/\1\x00\2\x01\3/
tl2
:l3
s/((\x00?[[:xdigit:]]\x01?){4})#/#\1 /
tl3
s/#((\x00?[[:xdigit:]]\x01?){4} ){8}/&#/
s/#(.*\x00[[:xdigit:] ]+)#/#\1\x01#/g
s/#([[:xdigit:] ]+\x01[[:xdigit:] ]+):/#\x00\1:/
s/^([[:xdigit:]]+):([[:xdigit:]]+):#([^:]*)#([^:]*):(.{16})(.{,16})$/\1: \3 \5\\n\2: \4 \6/
s/^(.*\x00.*)\\n/\1 ###\\n/
:l4
s/^([^\\n]*)\x00/\1\x1b\[31m/
s/^([^\\n]*)\x01/\1\x1b\[m/
tl4
P
D"$ xxd random.bin | ./xxdgrep.sh bf5a9c61 # コードブロックなので伝わらないが、ちゃんとc2の部分が赤色になる
00000000: 96fe 0009 a4f2 69b3 eb42 8490 eb82 55c1 ......i..B....U.
00000010: 6cbd 125f 71f2 7aeb 2eea 2299 1305 255c l.._q.z..."...%\
00000020: 26b0 1620 b66e ba44 f0fd 5d1c fd34 820b &.. .n.D..]..4..
00000030: 9c5d 4359 a029 285c aec1 5ca1 8590 bf5a .]CY.)(\..\....Z ###
00000040: 9c61 e1fd c9dd 417d bd1c 97fc 0b8e 2641 .a....A}......&A ###
00000050: 401b 809f d621 17d8 f522 5e24 afbe bd82 @....!..."^$....
00000060: 3af2 1976 badf 4633 8cea 37e2 4cb9 e39f :..v..F3..7.L...
00000070: 5ecd 42d2 06fd 40d9 3b6c 6c41 9355 8322 ^.B...@.;llA.U."
00000080: c3ff eaef 0408 abfa 36ba 912d a0c2 90fe ........6..-....
00000090: 07b5 5830 3d67 2334 849e e6aa 1450 7cf1 ..X0=g#4.....P|.
000000a0: df2a 579b 107d 8e99 48f5 dd72 d733 00db .*W..}..H..r.3..
000000b0: edc1 87dc 1b0e 3acb 83dd 02d1 06d7 3069 ......:.......0i
000000c0: 5d80 b079 e851 94cd ]..y.Q..
何が起きているか
s コマンドとラベルを使ってゴリ押しを繰り返している
全部を詳細に書くとキリがないので、pattern spaceが大まかにどのような変遷を遂げているかを書いておく
00000010: 6cbd 125f 71f2 7aeb 2eea 2299 1305 255c l.._q.z..."...%\ |
00000010: 6cbd 125f 71f2 7aeb 2eea 2299 1305 255c l.._q.z..."...%\00000020: 26b0 1620 b66e ba44 f0fd 5d1c fd34 820b &.. .n.D..]..4.. |
00000010:00000020:#6cbd 125f 71f2 7aeb 2eea 2299 1305 255c 26b0 1620 b66e ba44 f0fd 5d1c fd34 820b:l.._q.z..."...%\&.. .n.D..]..4.. |
00000010:00000020:6cbd#125f 71f2 7aeb 2eea 2299 1305 255c 26b0 1620 b66e ba44 f0fd 5d1c fd34 820b:l.._q.z…"…%\&.. .n.D..]..4.. |
| 中略(#が徐々に右にずれていき、hex部分のスペースが詰められている) |
00000010:00000020:6cbd125f71f27aeb2eea22991305255c26b01620b66eba44f0fd5d1cfd34820b#:l.._q.z…"…%\&.. .n.D..]..4.. |
↓ \x00から\x01の間が赤くなるように囲う(囲っている文字のバイナリに深い意味はない) |
00000010:00000020:6cbd125f71f27aeb2eea22991305255\x00c2\x016b01620b66eba44f0fd5d1cfd34820b#:l.._q.z…"…%\&.. .n.D..]..4.. |
00000010:00000020:6cbd125f71f27aeb2eea22991305255\x00c2\x016b01620b66eba44f0fd5d1cfd3#4820b :l.._q.z…"…%\&.. .n.D..]..4.. |
| 中略(#が徐々に左にずれていき、hex部分のスペースが空く) |
00000010:00000020:#6cbd 125f 71f2 7aeb 2eea 2299 1305 255\x00c 2\x016b0 1620 b66e ba44 f0fd 5d1c fd34 820b:l.._q.z…"…%\&.. .n.D..]..4.. |
| ↓改行を挟んでも色変更の整合がつくように調整をする |
00000010:00000020:#6cbd 125f 71f2 7aeb 2eea 2299 1305 255\x00c \x01#\x002\x016b0 1620 b66e ba44 f0fd 5d1c fd34 820b:l.._q.z…"…%\&.. .n.D..]..4.. |
00000010: 6cbd 125f 71f2 7aeb 2eea 2299 1305 255\x00c\x01 l.._q.z..."...%\00000020: \x002\x016b0 1620 b66e ba44 f0fd 5d1c fd34 820b &.. .n.D..]..4.. |
00000010: 6cbd 125f 71f2 7aeb 2eea 2299 1305 255\x00c\x01 l.._q.z..."...%\ ###00000020: \x002\x016b0 1620 b66e ba44 f0fd 5d1c fd34 820b &.. .n.D..]..4.. |
00000010: 6cbd 125f 71f2 7aeb 2eea 2299 1305 255\x1b[31mc\x1b[m l.._q.z..."...%\ ###00000020: \x1b[31m2\x1b[m6b0 1620 b66e ba44 f0fd 5d1c fd34 820b &.. .n.D..]..4.. |
最後の最後に置換した文字列 \x1b[31m は文字色を赤色にするためのSGRパラメータとそれを出力するCSIである
詳細を知りたい人は大昔書いたQiitaを参考してほしい
大雑把には echo -e "\x1b[31mRED\x1b[m"すると出力が赤い文字になる